Appinio Research · 27.02.2025 · 5min Lesezeit

Bei Appinio sind hochwertige Daten das Herzstück der Insights, die wir liefern. Um die Datenintegrität zu wahren, setzen wir auf eine sorgfältige Balance zwischen fortschrittlichen maschinellen Lernwerkzeugen und dem Know-How unseres Forschungsteams.
Wie wir mit minderwertigen Antworten umgehen
Verschiedene Faktoren können zu schlechten Daten führen: Teilnehmende könnten ermüden, Fragen falsch interpretieren oder einfach nicht aufmerksam antworten. Um diese Probleme zu verringern, nutzen wir ein automatisiertes System, das klar definierte Probleme markiert. Darüber hinaus erkennen fortschrittliche ML-Modelle subtilere Muster, die auf minderwertige Antworten hindeuten können.
Wir achten auf häufige Warnsignale, wie sich wiederholende oder widersprüchliche Antworten, viel zu kurze Bearbeitungszeiten oder Unstimmigkeiten zwischen Antworten. Anschließend wenden wir automatisierte Überprüfungen in Kombination mit menschlicher Kontrolle an. Diese Vorgehensweise stellt sicher, dass verdächtige Antworten sorgfältig im Kontext der Studie bewertet werden, und hilft, unsere ML-Modelle im Laufe der Zeit zu verbessern.
Den richtigen Ausgleich finden
Die echte Herausforderung besteht darin, zwei Dinge gleichzeitig zu erreichen:
- So viele minderwertige Antworten wie möglich erfassen.
- Falsch-Positive minimieren, damit gültige Daten unberührt bleiben.
Sind die Filter zu strikt, werden echte Teilnehmende ausgeschlossen. Zu nachsichtige Filter könnten schlechte Antworten durchlassen. Unsere Lösung ist eine hybride Methode: leistungsfähiges maschinelles Lernen unterstützt durch menschliche Kontrolle. Nur durch die Kombination automatisierter Prozesse mit der Validierung durch Expertinnen und Experten können wir unsere hohen Qualitätsstandards einhalten.
Unser hybrider Prozess in Aktion
Derzeit klassifiziert unser ML-System den Großteil der Antworten mit hoher Effizienz und stuft sie mit großer Zuverlässigkeit als gültig oder ungültig ein. Für die wenigen Antworten, die unklar bleiben, greift unser Research-Operations-Team ein und prüft sie manuell. Auf diese Weise schützen wir nicht nur vor potenziellen Fehlern, sondern gewinnen auch wertvolle Einblicke, die unserem Modell bei der Feinabstimmung und Neuausrichtung helfen.
Eine Infrastruktur, die sich entwickelt
Wir haben eine Infrastruktur geschaffen, die sich ständig weiterentwickelt. Da sich das Nutzerverhalten ändert, benötigen unsere Modelle regelmäßige Updates. Wir sammeln kontinuierlich neue Daten, und unser System ist darauf ausgelegt, das Modell regelmäßig neu zu trainieren. So bleibt es mit aufkommenden Mustern Schritt für Schritt im Einklang.
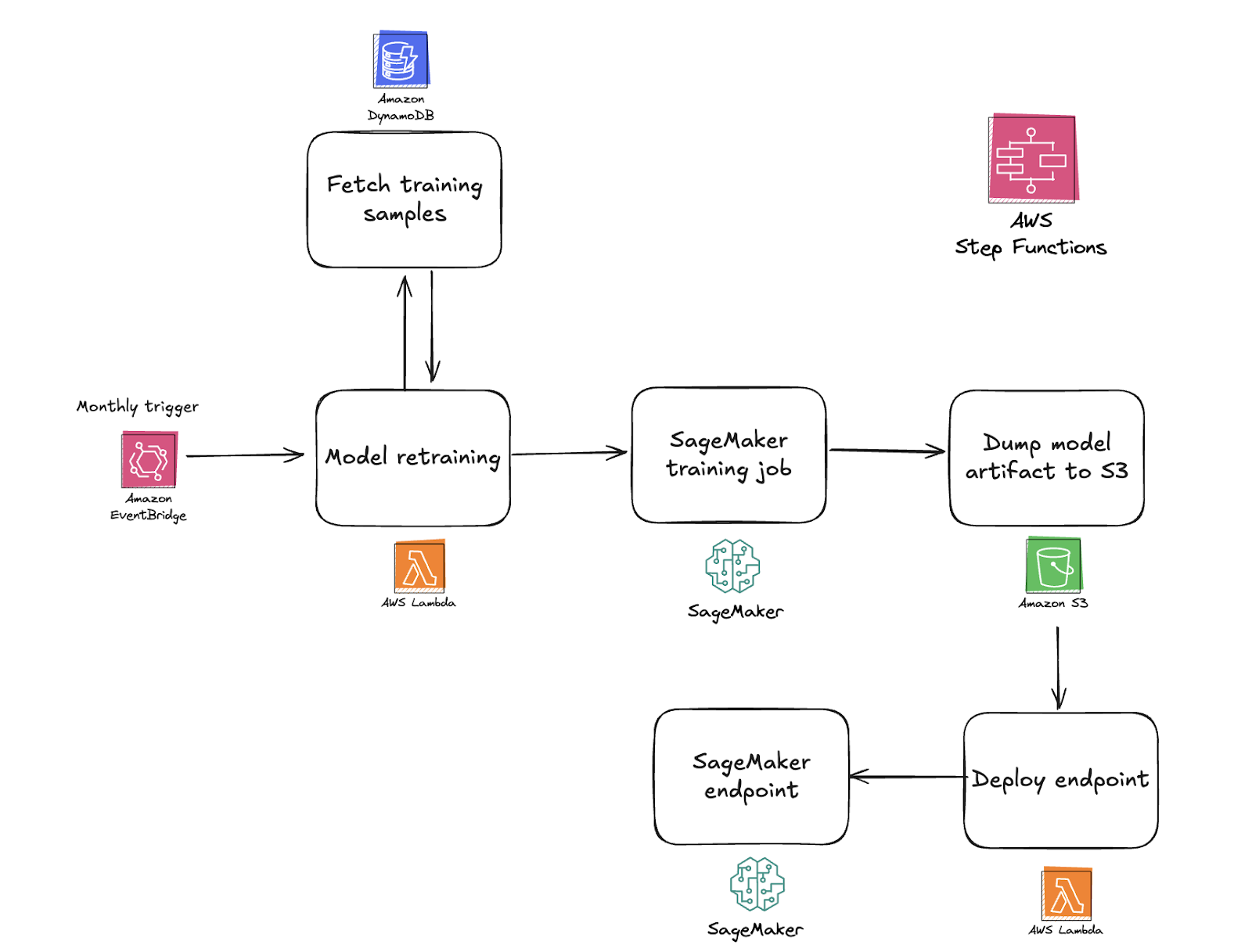
Bevor ein neu trainiertes Modell live geht, überprüfen wir wichtige Leistungskennzahlen und vergleichen sie mit früheren Benchmarks. Wenn das aktualisierte Modell genauer ist und keine Verzerrungen einführt, können wir es nahtlos einsetzen. Andernfalls behalten wir die bestehende Version bei. Dieser sorgfältige Ansatz gewährleistet Stabilität und ermöglicht gleichzeitig eine schnelle Anpassung.
Schutz vor Verzerrungen
Im gesamten Prozess ist es entscheidend, fair und objektiv zu bleiben. Wenn wir von ML generierte Daten in das Training einfließen lassen, besteht immer die Gefahr, Verzerrungen einzuführen oder zu verstärken. Hier kommt das menschliche Know-How ins Spiel—wir kombinieren algorithmische Kennzeichnungen mit sorgfältiger menschlicher Überprüfung. Der frühe Input von Menschen hilft dem Modell, das Wesentliche zu lernen, und die fortlaufende Aufsicht stellt sicher, dass alles im Lot bleibt und unbeabsichtigte Verzerrungen vermieden werden.
Das Modell
Wir nutzen ein starkes Klassifikationsmodell, das mit verschiedenen Datentypen umgehen kann und zuverlässig bleibt, selbst bei störungsbehafteten Daten. Während wir stets nach Möglichkeiten suchen, mit fortschrittlicheren Methoden zu verbessern, leistet unser aktuelles Modell bereits hervorragende Arbeit dabei, herauszufinden, welche Antworten genauer betrachtet werden müssen.
Bei der Entwicklung des Modells schaffen wir neue Merkmale unter Verwendung unserer Forschungsexpertise, indem wir subtile Signale einfügen, die helfen, echte Daten von potenziellem Betrug zu unterscheiden. Für die Bewertung konzentrieren wir uns auf zwei Hauptziele:
- Hohe Erkennungsrate bei minderwertigen Antworten – um möglichst viele problematische Antworten zu erfassen.
- Hohe Präzision bei gültigen Antworten – damit echte Daten nicht falsch markiert werden.
Da minderwertige Antworten eher selten sind, kann eine etwas höhere Falsch-Positiv-Rate bei ihnen die manuelle Arbeit erheblich reduzieren, ohne die Datenqualität zu beeinträchtigen. Gleichzeitig legen wir strengere Kriterien für gültige Antworten fest, um echte Daten so genau wie möglich zu halten.
Einen ausgewogenen Ansatz erreichen
Von Anfang an hat menschliches Fachwissen unseren von ML unterstützten Cleaning Prozess geprägt und dabei eine Balance zwischen Qualität und Praktikabilität geschaffen. Diese Zusammenarbeit zwischen Menschen und Technologie sorgt dafür, dass unsere Daten sowohl zuverlässig als auch flexibel bleiben – menschliche Kontrolle verhindert zu strenge Filterung, während die Automatisierung die Erkennung minderwertiger Antworten beschleunigt. Mit diesem Ansatz können wir uns an verändertes Verhalten von Befragten anpassen und unseren Kunden und Kundinnen konstant vertrauenswürdige Einblicke liefern.
Wenn Sie daran interessiert sind, wie Appinio Ihrem Unternehmen zu ähnlichen Ergebnissen verhelfen kann, nehmen Sie gerne Kontakt mit uns auf.


