Appinio Research · 27.02.2025 · 5min Tiempo de lectura

En Appinio, los datos de alta calidad son la base de los insights que ofrecemos. Mantener su integridad exige un equilibrio preciso entre herramientas avanzadas de aprendizaje automático (ML) y la experiencia de nuestro equipo de investigación.
Cómo abordamos las respuestas de baja calidad
Existen varios factores que pueden afectar la calidad de los datos: los participantes pueden fatigarse, interpretar mal las preguntas o simplemente no prestar atención a sus respuestas. Para minimizar estos problemas, utilizamos un sistema automatizado que detecta irregularidades bien definidas. Además, modelos avanzados de ML identifican patrones más sutiles que pueden indicar respuestas de baja calidad.
Nos fijamos en señales de alerta habituales, como respuestas repetitivas o contradictorias, tiempos de finalización demasiado cortos o inconsistencias entre respuestas. Luego, aplicamos controles automatizados combinados con una revisión humana. Este enfoque no solo garantiza que las respuestas sospechosas se evalúen dentro del contexto del estudio, sino que también ayuda a mejorar nuestros modelos de ML con el tiempo.
Encontrar el equilibrio perfecto
El verdadero reto es lograr dos cosas a la vez:
- Detectar el mayor número posible de respuestas de baja calidad.
- Minimizar falsos positivos para no afectar datos válidos.
Si los filtros son demasiado estrictos, pueden excluir a participantes legítimos. Si son demasiado flexibles, pueden dejar pasar respuestas de baja calidad. Nuestra solución es un método híbrido: un potente ML respaldado por supervisión humana. Solo al combinar procesos automatizados con validación experta podemos mantener estándares de calidad extremadamente rigurosos.
Nuestro proceso híbrido en acción
Actualmente, nuestro sistema de ML clasifica la gran mayoría de respuestas con gran precisión, etiquetándolas como válidas o inválidas con un alto grado de confianza. Para el pequeño porcentaje de respuestas ambiguas, nuestro equipo de Research Operations interviene y las revisa manualmente. Así, no solo evitamos posibles errores, sino que también generamos insights clave que ayudan a mejorar y ajustar el modelo.
Una infraestructura en constante evolución
Hemos diseñado una infraestructura que mejora de forma continua. El comportamiento de los usuarios cambia, por lo que nuestros modelos necesitan actualizaciones regulares. Recogemos nuevos datos de forma constante y nuestro sistema está configurado para reentrenar el modelo periódicamente, asegurando que se adapte a patrones emergentes.
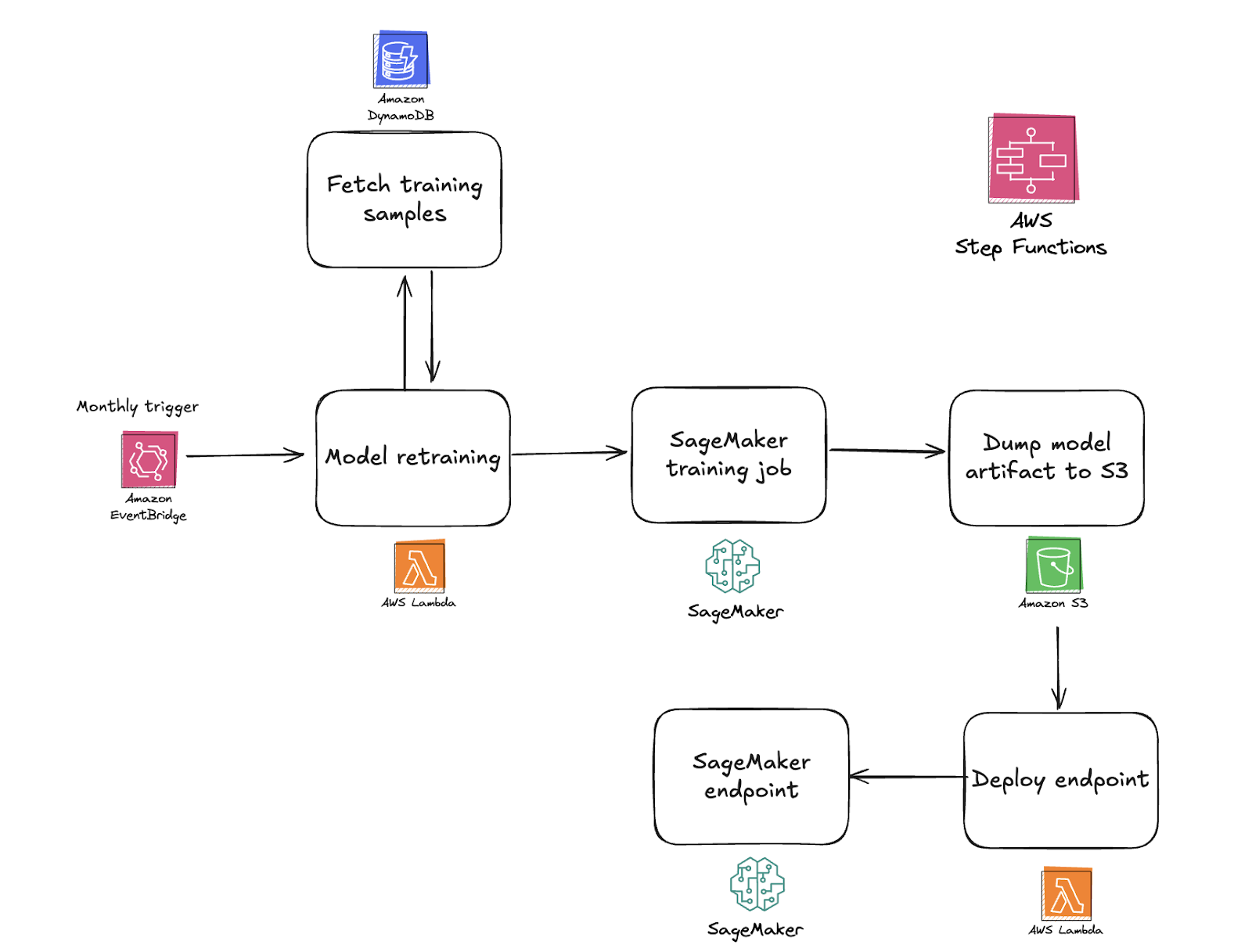
Antes de implementar un modelo reentrenado, revisamos métricas clave y las comparamos con referencias previas. Si el nuevo modelo es más preciso sin introducir sesgos, lo desplegamos sin problemas. De lo contrario, mantenemos la versión actual. Este enfoque garantiza estabilidad sin perder capacidad de adaptación.
Protección contra sesgos
A lo largo de todo el proceso, la imparcialidad y la objetividad son fundamentales. Al utilizar datos generados por ML en el entrenamiento, existe el riesgo de introducir o incluso amplificar sesgos. Ahí es donde entra en juego la experiencia humana: combinamos el etiquetado algorítmico con una revisión minuciosa. La intervención temprana de personas ayuda al modelo a aprender qué es realmente importante, mientras que la supervisión continua evita sesgos no intencionados a largo plazo.
El modelo
Utilizamos un modelo de clasificación robusto capaz de manejar distintos tipos de datos y mantenerse fiable incluso con información ruidosa. Aunque siempre buscamos formas de mejorar con métodos más avanzados, nuestro modelo actual identifica eficazmente qué respuestas requieren una revisión más detallada.
Al desarrollarlo, creamos nuevas características con base en nuestra experiencia en investigación, añadiendo señales sutiles que ayudan a diferenciar datos reales de posibles fraudes. Para su evaluación, nos centramos en dos objetivos clave:
- Alta sensibilidad para respuestas de baja calidad, detectando el mayor número posible de respuestas problemáticas.
- Alta precisión para respuestas válidas, asegurando que los datos genuinos no sean marcados erróneamente.
Dado que las respuestas de baja calidad son poco frecuentes, permitir una tasa de falsos positivos ligeramente mayor en ellas reduce significativamente el trabajo manual sin afectar la calidad de los datos. Al mismo tiempo, aplicamos umbrales más estrictos a las respuestas válidas para mantener la mayor precisión posible en los datos legítimos.
Conseguir un enfoque equilibrado
Desde el principio, la experiencia humana ha sido clave en nuestro proceso de limpieza basado en ML, equilibrando calidad y eficiencia. Esta colaboración entre personas y tecnología mantiene nuestros datos fiables y flexibles: la supervisión humana evita filtros excesivamente estrictos, mientras que la automatización agiliza la detección de respuestas de baja calidad. Gracias a este enfoque, nos adaptamos a los cambios en el comportamiento de los participantes y garantizamos insights fiables para nuestros clientes.
Si quieres saber cómo Appinio puede ayudar a tu negocio a lograr resultados similares, contáctanos.

