Appinio Research · 10.09.2024 · 38min Lesezeit

Haben Sie sich schon einmal gefragt, wie ein einfaches Konzept wie ein Entscheidungsbaum in der komplexen Welt des maschinellen Lernens leistungsstarke Erkenntnisse und Vorhersagen liefern kann?
Vom Verständnis ihrer inneren Funktionsweise bis hin zur Beherrschung der Kunst des Abstimmens und Optimierens werden Sie ein tiefes Verständnis dieser vielseitigen Modelle erlangen. Wir entmystifizieren Schlüsselkonzepte, erforschen verschiedene Entscheidungsbaum-Algorithmen und geben Ihnen die Werkzeuge an die Hand, mit denen Sie diese effektiv bewerten, interpretieren und einsetzen können.
Was ist ein Entscheidungsbaum?
Ein Entscheidungsbaum ist ein überwachter Algorithmus für maschinelles Lernen, der sowohl für Klassifizierungs- als auch für Regressionsaufgaben verwendet wird. Es handelt sich um eine baumartige Struktur, bei der ein interner Knoten ein Merkmal darstellt, der Zweig eine Entscheidungsregel und jeder Blattknoten ein Ergebnis.
Entscheidungsbäume werden in der Datenwissenschaft eingesetzt, um Entscheidungen oder Vorhersagen auf der Grundlage von Eingabemerkmalen zu treffen. Sie eignen sich hervorragend für die Verarbeitung sowohl kategorischer als auch numerischer Daten, was sie zu vielseitigen Werkzeugen für verschiedene Anwendungen macht.
Die Hauptzwecke von Entscheidungsbäumen sind:
- Klassifizierung: Entscheidungsbäume klassifizieren Datenpunkte in vordefinierte Kategorien oder Klassen. So können sie beispielsweise E-Mails als Spam oder Nicht-Spam klassifizieren, Kunden als potenzielle Käufer oder Nicht-Käufer und Patienten als an einer bestimmten Krankheit leidend oder nicht.
- Regression: Entscheidungsbäume sagen numerische Werte auf der Grundlage von Eingabemerkmalen voraus. Sie können Preise, Punktzahlen oder Mengen schätzen und eignen sich daher für Aufgaben wie die Vorhersage von Immobilienpreisen, Börsenprognosen und vieles mehr.
- Interpretierbarkeit: Entscheidungsbäume bieten eine verständliche Darstellung von Entscheidungsprozessen. Sie geben Aufschluss darüber, welche Merkmale für Vorhersagen entscheidend sind, was die Modellinterpretation erleichtert und sie in Bereichen wertvoll macht, in denen Transparenz unerlässlich ist, z. B. im Gesundheits- und Finanzwesen.
Bedeutung von Entscheidungsbäumen in der Datenwissenschaft
Entscheidungsbäume sind in der Datenwissenschaft und im maschinellen Lernen aus mehreren Gründen von großer Bedeutung:
- Leichte Interpretierbarkeit: Entscheidungsbäume sind von Natur aus interpretierbar. Die grafische Darstellung der Baumstruktur ermöglicht es Datenwissenschaftlern und Interessengruppen, die Logik hinter den Vorhersagen leicht zu verstehen. Diese Interpretierbarkeit ist in Bereichen, in denen Entscheidungsprozesse transparent sein müssen, von entscheidender Bedeutung.
- Vielseitigkeit: Entscheidungsbäume können verschiedene Datentypen verarbeiten, einschließlich kategorischer und numerischer Merkmale, ohne dass eine umfangreiche Vorverarbeitung erforderlich ist. Diese Vielseitigkeit vereinfacht die Datenvorbereitungsphase und beschleunigt die Modellentwicklung.
- Feature-Auswahl: Entscheidungsbäume liefern Bewertungen der Merkmalsbedeutung und helfen Datenwissenschaftlern bei der Identifizierung der Merkmale, die bei der Erstellung von Vorhersagen den größten Einfluss haben. Diese Fähigkeit zur Merkmalsauswahl hilft bei der Dimensionalitätsreduzierung und der Verbesserung der Modelleffizienz.
- Anwendbarkeit: Entscheidungsbäume werden in verschiedenen Bereichen eingesetzt, z. B. im Gesundheitswesen (Krankheitsdiagnose), im Finanzwesen (Kreditwürdigkeitsprüfung), im Marketing (Kundensegmentierung) und in der natürlichen Sprachverarbeitung (Stimmungsanalyse). Ihre Anpassungsfähigkeit an unterschiedliche Aufgaben zeigt ihre Relevanz in allen Branchen.
- Ensemble-Methoden: Entscheidungsbäume dienen als Bausteine für leistungsstarke Ensemble-Methoden wie Random Forests und Gradient Boosted Trees. Diese Ensemble-Techniken kombinieren mehrere Entscheidungsbäume, um die Vorhersagegenauigkeit und Robustheit zu verbessern.
Überblick über die Struktur von Entscheidungsbäumen
Ein typischer Entscheidungsbaum besteht aus den folgenden Komponenten:
- Wurzelknoten: Der oberste Knoten, der den gesamten Datensatz und den anfänglichen Entscheidungspunkt darstellt.
Interne Knoten: Knoten, die Merkmale oder Attribute darstellen und als Entscheidungspunkte für die Aufteilung der Daten dienen. - Verzweigungen: Pfeile, die Knoten verbinden und das Ergebnis einer Entscheidungsregel auf der Grundlage von Merkmalswerten angeben.
- Blattknoten: Endknoten, die das endgültige Vorhersage- oder Klassifizierungsergebnis darstellen.
- Entscheidungsregeln: Die Kriterien, die an internen Knoten zur Partitionierung der Daten verwendet werden, wie z. B. "wenn Merkmal A > X, gehe nach links; andernfalls gehe nach rechts".
Die Baumstruktur wird rekursiv durch einen Prozess aufgebaut, der als rekursive Partitionierung bekannt ist, bei der der Datensatz wiederholt in Teilmengen auf der Grundlage der gewählten Merkmale und Kriterien aufgeteilt wird, bis eine Abbruchbedingung erfüllt ist.
Allgemeine Anwendungsfälle
Entscheidungsbäume finden in einer Vielzahl von Branchen und Problembereichen Anwendung. Einige alltägliche Anwendungsfälle sind:
- Kundensegmentierung: Entscheidungsbäume helfen Unternehmen bei der Segmentierung ihres Kundenstamms für gezielte Marketingstrategien, z. B. bei der Identifizierung von Kunden mit hohem Wert oder beim Verständnis der Kundenpräferenzen.
- Kreditwürdigkeitsprüfung: Finanzinstitute verwenden Entscheidungsbäume, um die Kreditwürdigkeit von Kreditantragstellern zu bewerten und anhand verschiedener Faktoren zu entscheiden, ob ein Kreditantrag genehmigt oder abgelehnt werden soll.
- Diagnose im Gesundheitswesen: Mediziner verwenden Entscheidungsbäume zur Diagnose von Krankheiten, zur Vorhersage von Patientenergebnissen und zur Auswahl geeigneter Behandlungen auf der Grundlage von Symptomen und medizinischen Daten.
- Vorausschauende Wartung: In Branchen wie der Fertigungsindustrie und der Versorgungswirtschaft werden Entscheidungsbäume zur Vorhersage von Geräteausfällen und zur Planung von Wartungsarbeiten eingesetzt, um Ausfallzeiten und Betriebskosten zu reduzieren.
- Empfehlungssysteme: E-Commerce-Plattformen und Inhaltsanbieter verwenden Entscheidungsbäume, um Nutzern Produkte, Dienstleistungen oder Inhalte auf der Grundlage ihrer Präferenzen und ihres Verhaltens zu empfehlen.
- Erkennung von Anomalien: Entscheidungsbäume sind bei der Erkennung von Anomalien in verschiedenen Bereichen nützlich, z. B. bei der Erkennung von Betrug bei Finanztransaktionen oder bei der Erkennung von Netzwerkeinbrüchen im Bereich der Cybersicherheit.
Das Verständnis der Grundlagen von Entscheidungsbäumen bildet eine solide Grundlage für die effektive Nutzung dieses vielseitigen Algorithmus für maschinelles Lernen in Data-Science-Projekten. Unabhängig davon, ob Sie neu auf dem Gebiet sind oder bereits Erfahrung haben, bieten Entscheidungsbäume wertvolle Werkzeuge, um datengesteuerte Entscheidungen zu treffen und umsetzbare Erkenntnisse zu gewinnen.
Schlüsselkonzepte von Entscheidungsbäumen
Bevor wir uns näher mit dem Thema befassen, sollten wir einige der Schlüsselkonzepte untersuchen, die die Grundlage für Entscheidungsbäume bilden. Das Verständnis dieser Konzepte ist unerlässlich, um zu verstehen, wie Entscheidungsbäume funktionieren und wie Sie sie in Ihren Projekten zum maschinellen Lernen am besten einsetzen können.
Knoten und Kanten
Bei der Erörterung von Entscheidungsbäumen wird häufig auf Knoten und Kanten verwiesen. Lassen Sie uns diese grundlegenden Komponenten aufschlüsseln:
Knoten
Knoten sind die grundlegenden Bausteine eines Entscheidungsbaums. Jeder Knoten stellt einen Entscheidungspunkt oder einen Test für ein bestimmtes Merkmal des Datensatzes dar. Im Folgenden werden die verschiedenen Knotentypen näher betrachtet:
- Wurzelknoten: Dies ist der oberste Knoten des Baums, der die erste Entscheidung oder den ersten Test darstellt. Er dient als Startpunkt für den Entscheidungsprozess.
- Entscheidungsknoten: Diese Knoten folgen auf den Wurzelknoten und stellen Zwischenentscheidungen oder -tests dar. An jedem Entscheidungsknoten bewertet der Algorithmus den Wert eines Merkmals und entscheidet, welchem Zweig er folgen soll.
- Blattknoten: Die Endpunkte des Baums werden als Blattknoten bezeichnet. Sie liefern die endgültige Entscheidung oder Vorhersage. Bei einem Klassifizierungsproblem entspricht jeder Blattknoten einer Klassenbezeichnung, während er bei einer Regression einen vorhergesagten Wert darstellt.
Kanten
Kanten in einem Entscheidungsbaum sind die Verbindungslinien zwischen den Knoten. Sie veranschaulichen den Fluss der Entscheidungen von einem Knoten zum anderen und helfen Ihnen, den Entscheidungsprozess visuell zu verstehen.
In der Praxis bilden Knoten und Kanten zusammen eine baumartige Struktur, die den Algorithmus durch die Daten führt und schließlich zu einer Entscheidung oder Vorhersage führt.
Wurzelknoten, Entscheidungsknoten und Blattknoten
Um zu verstehen, wie Entscheidungen getroffen und Vorhersagen erstellt werden, ist es wichtig, die Rollen und Eigenschaften der verschiedenen Knotentypen in einem Entscheidungsbaum zu kennen.
Wurzelknoten
Der Wurzelknoten ist der Startpunkt des Entscheidungsbaums. Er stellt die erste Entscheidung oder den ersten Test dar, der auf die Eingabedaten angewendet wird. Alle anderen Knoten und Zweige gehen vom Wurzelknoten aus.
Entscheidungsknoten
Entscheidungsknoten, die auch als Zwischenknoten bezeichnet werden, erscheinen zwischen dem Wurzelknoten und den Blattknoten. Sie sind für die Auswertung bestimmter Merkmale oder Bedingungen in den Daten zuständig. Der Entscheidungsbaumalgorithmus verwendet Entscheidungsknoten, um die Daten auf der Grundlage der gewählten Kriterien in Teilmengen aufzuteilen.
Blattknoten
Am Ende jeder Verzweigung befinden sich die Blattknoten. Diese Knoten liefern die endgültige Ausgabe oder Vorhersage des Entscheidungsbaums. Bei Klassifizierungsaufgaben entspricht jeder Blattknoten einer Klassenbezeichnung, während die Blattknoten bei der Regression die vorhergesagten Werte enthalten.
Wenn Sie die Abfolge und den Fluss vom Stammknoten über die Entscheidungsknoten zu den Blattknoten verstehen, können Sie nachvollziehen, wie der Entscheidungsbaum zu seinen endgültigen Entscheidungen oder Vorhersagen gelangt.
Splitting-Kriterien
Einer der wichtigsten Aspekte beim Aufbau eines effektiven Entscheidungsbaums ist die Bestimmung, wie die Daten an den Entscheidungsknoten aufgeteilt werden sollen. Dieser Prozess beruht auf Aufteilungskriterien, die die Bedingungen definieren, unter denen die Daten in Teilmengen aufgeteilt werden.
Zu den Standardaufteilungskriterien gehören:
- Gini-Verunreinigung: Misst die Wahrscheinlichkeit, dass ein zufällig ausgewähltes Element falsch klassifiziert wird, wenn es gemäß der Verteilung der Klassen in der Teilmenge beschriftet würde.
- Entropie: Misst den Grad der Unordnung oder Unreinheit in einem Datensatz. Eine geringere Entropie weist auf eine homogenere Teilmenge hin.
- Mittlerer quadratischer Fehler (MSE): Wird bei Regressionsaufgaben verwendet und berechnet die Varianz der Zielvariablen in einer Teilmenge.
Die Wahl des Aufteilungskriteriums kann sich erheblich auf die Struktur und Leistung Ihres Entscheidungsbaums auswirken und ist oft eine wichtige Entscheidung im Modellierungsprozess.
Ausschneiden
Entscheidungsbäume können zwar komplex werden und die Trainingsdaten überfordern, aber es ist wichtig, dies durch eine Technik namens Pruning zu verhindern.
Beim Pruning werden Zweige oder Knoten aus dem Baum entfernt, die nicht wesentlich zur Verbesserung der Leistung des Modells bei ungesehenen Daten beitragen. Auf diese Weise wird eine Überanpassung vermieden, bei der der Baum das Rauschen in den Trainingsdaten aufnimmt und bei neuen Daten eine schlechte Leistung zeigt.
Das Pruning kann mit verschiedenen Methoden durchgeführt werden, z. B. mit dem Cost-Complexity Pruning, das darauf abzielt, das richtige Gleichgewicht zwischen Modellkomplexität und Vorhersagegenauigkeit zu finden.
Entscheidungsbaum-Algorithmen
Zur Erstellung von Entscheidungsbäumen werden verschiedene Algorithmen verwendet. Jeder Algorithmus hat seine eigenen Stärken und Schwächen und eignet sich für verschiedene Arten von Problemen. Im Folgenden finden Sie einen kurzen Überblick über einige gängige Entscheidungsbaum-Algorithmen:
- ID3 (Iterativer Dichotomiser 3): Dieser Algorithmus verwendet die Entropie als Aufteilungskriterium und ist in erster Linie für Klassifizierungsaufgaben geeignet.
- C4.5: Als Erweiterung von ID3 kann C4.5 sowohl Klassifikations- als auch Regressionsaufgaben bewältigen und verwendet Informationsgewinn oder Gewinnverhältnis als Aufteilungskriterium.
- CART (Klassifizierungs- und Regressionsbäume): CART ist vielseitig und kann sowohl Klassifizierungs- als auch Regressionsaufgaben bewältigen. Es verwendet die Gini-Verunreinigung für die Klassifizierung und den MSE für die Regression.
- Zufällige Wälder: Diese Ensemble-Methode kombiniert mehrere Entscheidungsbäume, um die Genauigkeit zu verbessern und die Überanpassung zu reduzieren.
- Gradient Boosted Trees: Ein Boosting-Algorithmus, der Entscheidungsbäume sequentiell aufbaut, wobei jeder die Fehler seines Vorgängers korrigiert.
Die Wahl des zu verwendenden Algorithmus hängt von Ihrem spezifischen Problem und den Eigenschaften des Datensatzes ab. Das Verständnis der Stärken und Schwächen der einzelnen Algorithmen ist entscheidend für fundierte Entscheidungen bei Ihren Projekten zum maschinellen Lernen.
In den nächsten Abschnitten werden wir uns mit der Erstellung von Entscheidungsbäumen, der Bewertung ihrer Leistung und der Optimierung ihrer Parameter befassen, um robuste und genaue Modelle zu erstellen.
Wie erstellt man einen Entscheidungsbaum?
Die Erstellung eines Entscheidungsbaums umfasst eine Reihe wichtiger Schritte, von der Vorbereitung Ihrer Daten über die Handhabung verschiedener Datentypen bis hin zur Bestimmung der optimalen Aufteilungskriterien. Lassen Sie uns diese Schritte im Detail untersuchen.
1. Datenvorbereitung und Vorverarbeitung
Eine angemessene Datenvorbereitung und -vorverarbeitung sind wesentliche Voraussetzungen für die Erstellung genauer Entscheidungsbäume. Im Folgenden erfahren Sie, wie Sie diesen entscheidenden Schritt angehen sollten:
- Datenbereinigung: Entfernen Sie alle doppelten oder irrelevanten Datensätze aus Ihrem Datensatz.
- Behandlung von Ausreißern: Entscheiden Sie, wie Sie Ausreißer behandeln wollen, indem Sie sie entfernen oder die Daten transformieren.
- Merkmalsskalierung: Je nach dem von Ihnen verwendeten Algorithmus sollten Sie überlegen, ob Sie Ihre Merkmale skalieren wollen, insbesondere bei Methoden, die auf die Größe der Merkmale reagieren.
- Merkmalstechnik: Erstellen Sie neue Merkmale oder transformieren Sie vorhandene, um die Leistung des Modells zu verbessern.
- Datenaufteilung: Teilen Sie Ihren Datensatz in einen Trainings- und einen Testdatensatz auf, um die Leistung des Modells effektiv zu bewerten.
Die Datenqualität wirkt sich direkt auf die Qualität des resultierenden Entscheidungsbaums aus, daher ist es wichtig, Zeit in diese Phase zu investieren. Die Verbesserung des Prozesses der Entscheidungsbaumerstellung durch fortschrittliche Datenerfassungs- und Analysemethoden kann zu robusteren und genaueren Ergebnissen führen.
Appinio bietet Ihnen einen rationellen und effizienten Ansatz für die Datenerfassung. Appinio ermöglicht Ihnen die Erfassung von Verbraucherdaten in Echtzeit und stellt Ihnen eine Fülle von Daten zur Verfügung, auf die Sie Ihre Entscheidungsbaummodelle stützen können.
Machen Sie den nächsten Schritt zur Optimierung Ihres Entscheidungsprozesses, indem Sie noch heute eine Demo mit Appinio buchen und die Vorteile datengestützter Erkenntnisse entdecken!
2. Die Auswahl der richtigen Splitting-Kriterien
Die Auswahl der richtigen Aufteilungskriterien für Ihren Entscheidungsbaum kann dessen Leistung erheblich beeinflussen. Im Folgenden finden Sie einen Überblick über die gängigen Kriterien und ihre Eignung:
- Gini-Verunreinigung: Ideal für Klassifizierungsprobleme, insbesondere wenn Sie Fehlklassifizierungen minimieren möchten.
- Entropie: Ähnlich wie die Gini-Unreinheit ist die Entropie eine gute Wahl für Klassifizierungsaufgaben, vor allem, wenn Sie eine ausgewogene Aufteilung wünschen.
- Mittlerer quadratischer Fehler (MSE): MSE wird in erster Linie für Regressionsprobleme verwendet und minimiert die Varianz innerhalb von Teilmengen.
- Informationsgewinn: Ein Kriterium, das die Verringerung der Entropie oder Gini-Verunreinigung nach einer Aufteilung misst. Es ist für Klassifikationsprobleme geeignet.
- Verstärkungsverhältnis: Ein informationsbasiertes Kriterium, das die Anzahl der Kategorien in einem Merkmal berücksichtigt. Es ist vorteilhaft, wenn es sich um kategoriale Merkmale mit einer unterschiedlichen Anzahl von Klassen handelt.
Die Wahl des Aufteilungskriteriums sollte auf Ihr spezifisches Problem und die Merkmale Ihres Datensatzes abgestimmt sein, da es die Art und Weise beeinflusst, wie der Entscheidungsbaum die Daten aufteilt.
3. Rekursive Partitionierung
Die rekursive Partitionierung ist das Herzstück der Erstellung eines Entscheidungsbaums. Es handelt sich dabei um den Prozess der wiederholten Aufteilung des Datensatzes in Teilmengen auf der Grundlage der gewählten Aufteilungskriterien. Und so funktioniert es:
- Startpunkt: Der Wurzelknoten stellt den gesamten Datensatz dar.
- Aufteilung: Der Algorithmus wählt das beste Merkmal und den besten Aufteilungspunkt entsprechend dem gewählten Kriterium aus und erstellt Kindknoten.
- Unterknoten: Jeder Unterknoten stellt eine kleinere Teilmenge der Daten dar.
- Rekursion: Der Prozess wird für jeden Kindknoten rekursiv wiederholt, bis ein Stoppkriterium erfüllt ist (z. B. eine maximale Tiefe erreicht ist oder eine Mindestanzahl von Stichproben pro Blattknoten).
Die rekursive Partitionierung wird so lange fortgesetzt, bis alle Blätter rein sind (bei Klassifizierungsproblemen gehören alle Instanzen in einem Blattknoten zur gleichen Klasse) oder bis die Haltebedingungen erfüllt sind.
4. Behandlung fehlender Werte
Der Umgang mit fehlenden Werten ist eine häufige Herausforderung bei der Arbeit mit realen Datensätzen. Bei Entscheidungsbäumen ist es entscheidend, fehlende Werte effektiv zu behandeln, um verzerrte Aufteilungen und ungenaue Vorhersagen zu vermeiden:
- Imputation: Sie können fehlende Werte durch einen bestimmten Wert ersetzen (z. B. den Mittelwert oder Median für numerische Merkmale) oder Techniken wie Forward-Fill oder Backward-Fill für Zeitseriendaten verwenden.
- Besondere Behandlung: Für kategoriale Merkmale können Sie eine separate Kategorie für fehlende Werte erstellen.
- Splitting-Strategie: Bei einigen Algorithmen können fehlende Werte als separater Zweig im Baum behandelt werden, so dass das Modell den besten Pfad für fehlende Daten wählen kann.
Welchen Ansatz Sie wählen, hängt von der Art der Daten und dem spezifischen Entscheidungsbaumalgorithmus ab, den Sie verwenden.
5. Behandlung kategorischer Daten
Entscheidungsbäume können natürlich auch mit kategorialen Daten umgehen, aber Sie müssen wissen, wie Sie diese effektiv behandeln können:
- One-Hot-Codierung: Konvertieren kategorischer Variablen in binäre Spalten (0 oder 1) für jede Kategorie.
- Label-Kodierung: Weisen Sie kategorischen Werten numerische Bezeichnungen zu. Seien Sie jedoch vorsichtig, da dies zu unbeabsichtigten ordinalen Beziehungen führen kann.
- Ordinale Kodierung: Wird verwendet, wenn kategoriale Daten eine natürliche Reihenfolge haben, wie "niedrig", "mittel" und "hoch".
- Entscheidungsbaum-Algorithmen: Einige Algorithmen, wie ID3 und C4.5, können kategoriale Daten direkt ohne Kodierung verarbeiten.
Die Wahl der Kodierungsmethode hängt von der Art der kategorialen Daten und dem verwendeten Entscheidungsbaumalgorithmus ab. Durch die Wahl des richtigen Ansatzes wird sichergestellt, dass der Algorithmus die Informationen in Ihren kategorialen Merkmalen effektiv erfasst. Mit diesen wichtigen Schritten im Hinterkopf sind Sie gut gerüstet, um robuste und genaue Entscheidungsbäume zu erstellen, die verschiedene Datentypen verarbeiten und aussagekräftige Erkenntnisse liefern können.
Entscheidungsbaum-Algorithmen
Die Algorithmen für Entscheidungsbäume spielen eine entscheidende Rolle bei der Bestimmung der Leistungsfähigkeit Ihres Modells. Jeder Algorithmus hat seine eigenen Merkmale, Stärken und Schwächen. Im Folgenden werden einige der beliebtesten Entscheidungsbaum-Algorithmen im Detail untersucht.
ID3 (Iterativer Dichotomisierer 3)
ID3 (Iterative Dichotomiser 3) war einer der frühesten Entscheidungsbaumalgorithmen, der von Ross Quinlan entwickelt wurde. Auch wenn er heute weniger häufig verwendet wird, ist das Verständnis seiner Prinzipien wichtig, um die Entwicklung der Entscheidungsbaumalgorithmen zu verstehen.
Hauptmerkmale von ID3:
- Entropie-basiertes Splitting: ID3 verwendet die Entropie als Aufteilungskriterium. Ziel ist es, den Informationsgewinn bei jeder Aufteilung zu maximieren, indem die Entropie oder Unsicherheit in den resultierenden Teilmengen minimiert wird.
- Kategorische Daten: ID3 funktioniert gut mit kategorischen Daten und ist für Klassifizierungsaufgaben geeignet.
- Kein Pruning: ID3 beinhaltet kein Pruning, was zu einer Überanpassung der Trainingsdaten führen kann, wenn der Baum zu tief wachsen darf.
Trotz seiner historischen Bedeutung hat ID3 einige Einschränkungen, wie z. B. die Unfähigkeit, kontinuierliche Daten zu verarbeiten und die Anfälligkeit für Overfitting. Daher wurden modernere Algorithmen entwickelt.
C4.5
C4.5 ist eine Erweiterung von ID3, die ebenfalls von Ross Quinlan entwickelt wurde, um einige seiner Einschränkungen zu beseitigen und eine bessere Leistung zu erzielen.
Hauptmerkmale von C4.5:
- Entropie und Verstärkungsverhältnis: C4.5 hat das Konzept der Verwendung von Gain Ratio als Splitting-Kriterium eingeführt, das die Verzerrung von ID3 in Richtung von Attributen mit mehr Kategorien behebt.
- Handhabung kontinuierlicher Daten: C4.5 kann sowohl mit kategorialen als auch mit kontinuierlichen Daten umgehen und ist damit vielseitig einsetzbar.
- Beschneidung: Im Gegensatz zu ID3 beinhaltet C4.5 Pruning-Techniken, um eine Überanpassung zu verhindern und die Generalisierung des Entscheidungsbaums zu verbessern.
- Breite Anwendbarkeit: C4.5 ist für Klassifizierungs- und Regressionsaufgaben geeignet.
Die Fähigkeit von C4.5, sowohl kategoriale als auch kontinuierliche Daten zu verarbeiten, sowie seine Beschneidungsfunktionen machen es im Vergleich zu ID3 zu einer robusteren Wahl.
CART (Klassifizierungs- und Regressionsbäume)
CART (Classification and Regression Trees) ist ein vielseitiger Entscheidungsbaum-Algorithmus, der von Leo Breiman eingeführt wurde. Er kann sowohl Klassifizierungs- als auch Regressionsaufgaben bewältigen, weshalb er in der Praxis weit verbreitet ist.
Hauptmerkmale von CART:
- Gini-Unreinheit und mittlerer quadratischer Fehler: CART verwendet die Gini-Unreinheit als Standard-Aufteilungskriterium für Klassifizierungsaufgaben. Für die Regression wird der mittlere quadratische Fehler (MSE) verwendet.
- Binäre Bäume: CART konstruiert binäre Bäume, d. h. jeder Knoten hat zwei Kindknoten, was die Baumstruktur vereinfacht.
- Beschneidung: Ähnlich wie C4.5 beinhaltet CART Pruning-Techniken, um eine Überanpassung zu vermeiden.
- Merkmal Wichtigkeit: CART kann die Wichtigkeit jedes Merkmals berechnen und so ermitteln, welche Merkmale am meisten zu den Entscheidungen des Modells beitragen.
Die Fähigkeit von CART, sowohl Klassifizierungs- als auch Regressionsaufgaben zu bewältigen, und die Analyse der Merkmalsbedeutung machen es zu einer leistungsstarken Lösung für eine Vielzahl von Machine-Learning-Problemen.
Random Forests
Random Forests ist eine Ensemble-Lernmethode, die Entscheidungsbäume nutzt, um eine höhere Genauigkeit zu erzielen und die Überanpassung zu reduzieren.
Hauptmerkmale von Random Forests:
- Bagging: Random Forests erstellen mehrere Entscheidungsbäume durch Bootstrapping der Trainingsdaten (Stichproben mit Ersetzung) und Aggregation ihrer Vorhersagen.
- Zufällige Feature-Auswahl: Jeder Baum in einem Random Forest berücksichtigt bei der Entscheidungsfindung nur eine zufällige Teilmenge von Merkmalen. Dadurch wird das Risiko einer Überanpassung verringert.
- Hohe Genauigkeit: Random Forests sind für ihre hohe Genauigkeit und Robustheit bekannt, wodurch sie sich für verschiedene Anwendungen eignen.
- Merkmalsbedeutung: Random Forests können die Wichtigkeit von Merkmalen messen und so Aufschluss darüber geben, welche Merkmale am einflussreichsten sind.
Random Forests zeichnen sich in Szenarien aus, in denen Entscheidungsbäume allein zu ungenau sein könnten, was sie zu einer beliebten Wahl für komplexe Aufgaben macht.
Gradient Boosted Trees
Gradient Boosted Trees (GBTs) ist eine weitere Ensemble-Methode, die die Stärken von Entscheidungsbäumen in einer sequentiellen Weise kombiniert.
Hauptmerkmale von Gradient Boosted Trees:
- Verstärkung: GBTs bauen eine Folge von Entscheidungsbäumen auf, wobei jeder nachfolgende Baum die Fehler der vorangegangenen korrigiert.
- Gradienter Abstieg: Beim Gradient Boosting wird der Gradientenabstieg verwendet, um die Residuen oder Fehler in den Vorhersagen des Modells zu minimieren.
- Starke Vorhersagekraft: GBTs erreichen oft eine hohe Vorhersagegenauigkeit und erfassen effektiv komplexe Beziehungen in den Daten.
- Empfindlichkeit gegenüber Hyperparametern: Die Abstimmung der Hyperparameter ist entscheidend, um eine Überanpassung bei GBTs zu verhindern.
GBTs sind für eine Vielzahl von Aufgaben gut geeignet, insbesondere wenn es darum geht, die Vorhersagegenauigkeit zu maximieren und komplexe Muster in den Daten zu erfassen.
Jeder Entscheidungsbaum-Algorithmus hat seine eigenen Merkmale und eignet sich für unterschiedliche Szenarien. Die Wahl des zu verwendenden Algorithmus hängt von der Art Ihrer Daten, dem spezifischen Problem, das Sie angehen, und der gewünschten Modellleistung ab. Wenn Sie sich weiter mit Entscheidungsbäumen beschäftigen, sollten Sie mit diesen Algorithmen experimentieren, um die beste Lösung für Ihre Machine Learning-Projekte zu finden.
Wie werden Entscheidungsbäume evaluiert?
Die Bewertung der Leistung von Entscheidungsbäumen ist entscheidend, um sicherzustellen, dass sie genaue und zuverlässige Vorhersagen liefern. Im Folgenden werden die Metriken und Techniken zur Bewertung von Klassifizierungs- und Regressionsbäumen sowie Strategien zur Vermeidung von Überanpassung und Unteranpassung erläutert.
Metriken für Klassifizierungsbäume
Bei Klassifizierungsproblemen helfen mehrere Metriken dabei, die Effektivität von Entscheidungsbäumen zu beurteilen:
Genauigkeit
Die Genauigkeit misst den Anteil der korrekt klassifizierten Instanzen an der Gesamtzahl der Instanzen im Datensatz. Sie ist eine der einfachsten Metriken für die Klassifizierung.
Genauigkeit = (Anzahl der korrekten Vorhersagen) / (Gesamtzahl der Vorhersagen)
Bei unausgewogenen Datensätzen, bei denen eine Klasse deutlich in der Überzahl ist, ist die Genauigkeit jedoch möglicherweise nicht die beste Metrik.
Präzision und Rückruf
Die Präzision misst den Anteil der richtigen positiven Vorhersagen an allen positiven Vorhersagen:
Präzision = (Wahr-Positive) / (Wahr-Positive + Falsch-Positive)
Recall misst den Anteil der wahrhaft positiven Vorhersagen an allen tatsächlich positiven Vorhersagen:
Recall = (Wahr-Positive) / (Wahr-Positive + Falsch-Negative)
Diese Metriken sind besonders nützlich, wenn die Kosten für falsch-positive und falsch-negative Ergebnisse sehr unterschiedlich sind.
F1-Score
Der F1-Score ist das harmonische Mittel aus Precision und Recall und stellt ein Gleichgewicht zwischen beiden dar:
F1-Score = 2 * (Präzision * Rückruf) / (Präzision + Rückruf)
Dies ist eine gute Wahl, wenn Sie sowohl falsch-positive als auch falsch-negative Ergebnisse berücksichtigen wollen.
Metriken für Regressionsbäume
Bei der Bearbeitung von Regressionsaufgaben benötigen Sie verschiedene Metriken, um die Leistung von Entscheidungsbäumen zu bewerten:
Mittlerer absoluter Fehler (MAE)
Der mittlere absolute Fehler (MAE) misst die durchschnittliche absolute Differenz zwischen den vorhergesagten Werten und den tatsächlichen Werten:
MAE = Σ|Ist - Vorhersage| / n
Wobei:
- Σ bezeichnet die Summierung über alle Instanzen.
- n ist die Gesamtzahl der Instanzen.
- Im Vergleich zu anderen Metriken istMAE relativ robust gegenüber Ausreißern.
Mittlerer quadratischer Fehler (MSE)
Der mittlere quadratische Fehler (Mean Squared Error, MSE) berechnet die durchschnittliche quadratische Differenz zwischen den vorhergesagten und den tatsächlichen Werten:
MSE = Σ(Tatsächlicher - vorhergesagter)^2 / n
MSE gewichtet größere Fehler stärker und ist empfindlich gegenüber Ausreißern.
R-Quadrat (R²)
R-Quadrat (R²) misst den Anteil der Varianz in der abhängigen Variable, der durch die unabhängigen Variablen vorhersagbar ist. Es reicht von 0 bis 1, wobei höhere Werte eine bessere Anpassung anzeigen:
R² = 1 - (Σ(Tatsächlich - Vorhersage)^2) / (Σ(Tatsächlich - Mittelwert(tatsächlich))^2)
R-Quadrat hilft bei der Bewertung der Anpassungsfähigkeit des Regressionsmodells.
Kreuzvalidierung
Die Kreuzvalidierung ist eine wichtige Technik zur Bewertung von Entscheidungsbäumen und zur Sicherstellung ihrer Verallgemeinerung auf ungesehene Daten. Beliebte Kreuzvalidierungsmethoden sind die k-fache Kreuzvalidierung und die Leave-one-out-Kreuzvalidierung. Diese Methoden helfen bei der Beurteilung, wie gut das Modell auf verschiedenen Teilmengen der Daten funktioniert, und können potenzielle Probleme der Überanpassung aufzeigen.
Überanpassung und Unteranpassung
Eine der größten Herausforderungen bei der Arbeit mit Entscheidungsbäumen besteht darin, das richtige Gleichgewicht zwischen Overfitting und Underfitting zu finden:
- Überanpassung: Tritt auf, wenn der Baum zu komplex ist und das Rauschen in den Trainingsdaten erfasst, aber bei neuen Daten eine schlechte Leistung zeigt. Dies kann durch Beschneidung des Baums oder Begrenzung seiner Tiefe gemildert werden.
- Unteranpassung: Tritt auf, wenn der Baum zu einfach ist und die zugrunde liegenden Muster in den Daten nicht erfasst. Dies lässt sich beheben, indem man den Baum tiefer wachsen lässt oder komplexere Algorithmen verwendet.
Um einen Entscheidungsbaum zu erstellen, der sich gut auf ungesehene Daten verallgemeinern lässt, ist es wichtig, diese beiden Extreme auszugleichen. Die Kreuzvalidierung und die Abstimmung der Hyperparameter sind wertvolle Hilfsmittel für den Umgang mit Überanpassung und Unteranpassung.
Abstimmung und Optimierung von Entscheidungsbäumen
Um das volle Potenzial von Entscheidungsbäumen auszuschöpfen, müssen Sie sie optimieren und ihre Parameter fein abstimmen. Im Folgenden werden verschiedene Strategien für die Optimierung untersucht:
Abstimmung der Hyperparameter
Bei Hyperparametern handelt es sich um Einstellungen, die Sie anpassen können, um die Leistung Ihres Entscheidungsbaums zu optimieren. Zu den üblichen Hyperparametern gehören:
- Maximale Tiefe: Begrenzung der Tiefe des Baums, um eine Überanpassung zu verhindern.
- Mindeststichproben pro Blatt: Festlegen einer Mindestanzahl von Stichproben, die zum Erstellen eines Blattknotens erforderlich sind.
- Mindeststichproben pro Split: Festlegen einer Mindestanzahl von Stichproben, die für die Aufteilung eines Knotens erforderlich sind.
- Kriterium: Auswahl zwischen Gini-Verunreinigung und Entropie für die Klassifizierung oder MSE für die Regression.
Die Abstimmung der Hyperparameter beinhaltet das Experimentieren mit verschiedenen Kombinationen von Hyperparametern, um die beste Konfiguration für Ihr spezifisches Problem zu finden. Techniken wie die Gittersuche oder die Zufallssuche können verwendet werden, um den Hyperparameterraum systematisch zu erkunden.
Auswahl der Merkmale
Nicht alle Merkmale tragen gleichermaßen zum Entscheidungsprozess eines Entscheidungsbaums bei. Bei der Feature-Auswahl werden nur die relevantesten Features identifiziert und verwendet, was zu einem besser interpretierbaren und effizienteren Modell führen kann. Mithilfe von Techniken wie Feature Importance Scores können Sie feststellen, welche Features am einflussreichsten sind.
Umgang mit unausgewogenen Daten
In realen Szenarien sind Datensätze oft unausgewogen, d. h. eine Klasse überwiegt die anderen deutlich. Um mit unausgewogenen Daten umzugehen, sollten Sie Techniken wie diese in Betracht ziehen:
- Resampling: Oversampling der Minderheitenklasse oder Subsampling der Mehrheitsklasse, um den Datensatz auszugleichen.
- Synthetische Datengenerierung: Verwenden Sie Techniken wie Synthetic Minority Over-sampling Technique (SMOTE), um synthetische Instanzen der Minderheitenklasse zu erzeugen.
- Kostensensitives Lernen: Passen Sie die Fehlklassifizierungskosten an, um der Minderheitsklasse mehr Gewicht zu verleihen.
Umgang mit Multiklassen-Klassifikation
Obwohl Entscheidungsbäume von Natur aus für die binäre Klassifizierung geeignet sind, können sie auch für die Mehrklassenklassifizierung erweitert werden. Übliche Ansätze sind:
- Eins-vs-Rest (OvR): Ein binärer Klassifikator wird für jede Klasse trainiert, wobei diese als positive Klasse und die anderen als negative Klasse behandelt werden.
- Multinomiale Klassifizierung: Einige Algorithmen, wie C4.5 und CART, können Multiklassen-Klassifikation direkt verarbeiten, indem sie die Daten in jedem Knoten in mehrere Kategorien aufteilen.
Der effiziente Umgang mit der Multiklassenklassifizierung erfordert ein Verständnis der Feinheiten Ihres spezifischen Problems und die Auswahl der am besten geeigneten Strategie.
Die Optimierung von Entscheidungsbäumen durch die Abstimmung von Hyperparametern, die Auswahl von Merkmalen, den Umgang mit unausgewogenen Daten und die Bewältigung von Herausforderungen bei der Multiklassenklassifizierung kann ihre Leistung und Anwendbarkeit in realen Machine-Learning-Projekten erheblich verbessern.
Wie visualisiert man Entscheidungsbäume?
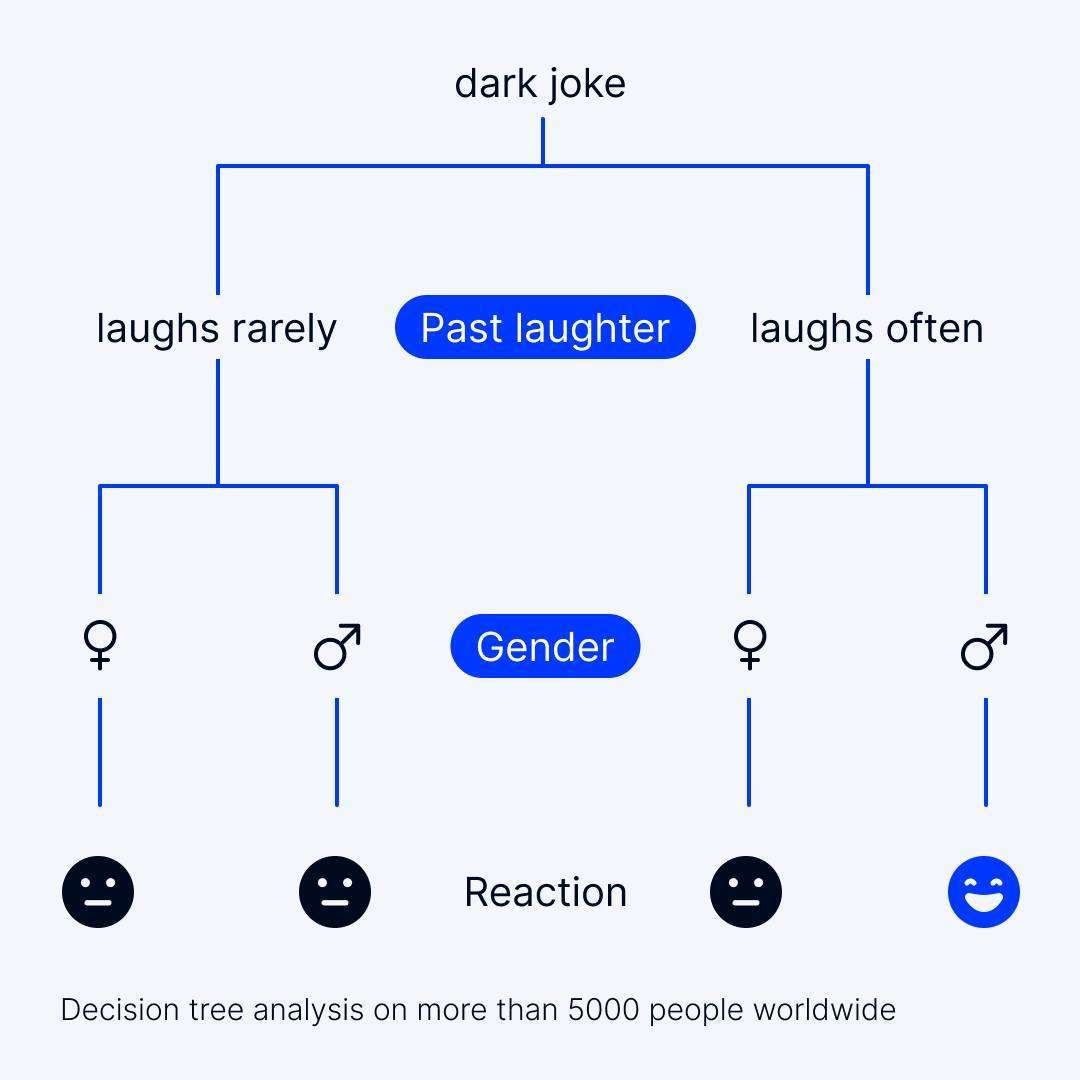
Entscheidungsbäume zu interpretieren und ihre Vorhersagen verständlich zu machen, ist sowohl für die Modellentwicklung als auch für die Kommunikation mit den Interessengruppen von entscheidender Bedeutung. Hier untersuchen wir verschiedene Aspekte der Interpretierbarkeit und Visualisierung.
Visualisierung von Entscheidungsbäumen
Die Visualisierung von Entscheidungsbäumen hilft Ihnen, ihre Struktur und ihren Entscheidungsprozess zu verstehen. Zu den Visualisierungstechniken gehören:
- Grafische Darstellungen: Sie können visuelle Darstellungen von Entscheidungsbäumen erstellen, in denen Knoten, Kanten und Entscheidungskriterien angezeigt werden. Beliebte Bibliotheken wie Graphviz oder Visualisierungstools, die von Frameworks für maschinelles Lernen bereitgestellt werden, sind für diesen Zweck hilfreich.
- Baumdiagramme: Die Darstellung des Entscheidungsbaums als Baumdiagramm mit Knoten und Verzweigungen hilft dabei, die Entscheidungslogik des Modells explizit zu machen.
- Knotenattribute: Erweitern Sie die Visualisierungen mit Informationen wie Merkmalsnamen, Aufteilungskriterien und Klassenbezeichnungen.
Visualisierungen helfen nicht nur beim Verständnis der Funktionsweise des Modells, sondern auch bei der Vermittlung der Ergebnisse an nichttechnische Beteiligte.
Wichtigkeit der Merkmale
Wenn Sie die Bedeutung der verschiedenen Merkmale in Ihrem Entscheidungsbaummodell verstehen, können Sie die Auswahl der Merkmale steuern und wertvolle Erkenntnisse gewinnen. Zu den Techniken zur Beurteilung der Bedeutung von Merkmalen gehören:
- Gini-Bedeutung: Bei Klassifikationsbäumen misst die Gini-Bedeutung, wie viel jedes Merkmal zur Reduzierung der Gini-Verunreinigung insgesamt beiträgt.
- Informationsgewinn oder Gain Ratio: Diese Maße bewerten den Informationsgewinn, der jedem Merkmal bei der Aufteilung des Baums zugeschrieben wird.
- Mittlere Abnahme der Genauigkeit (Mean Decrease in Accuracy, MDA): Bei Ensemble-Methoden wie Random Forests misst MDA die Auswirkung der einzelnen Merkmale auf die Modellgenauigkeit, wenn das Merkmal entfernt wird.
Durch die Identifizierung der einflussreichsten Merkmale können Sie sich bei der Entwicklung von Merkmalen auf diese konzentrieren und Einblicke in die zugrunde liegenden Datenmuster gewinnen.
Erklärbarkeit und Modellinterpretation
Obwohl Entscheidungsbäume von Natur aus interpretierbar sind, ist es dennoch wichtig, ihre Entscheidungen auch Nicht-Experten oder Stakeholdern zu erklären. Zu den Techniken für die Modellinterpretation gehören:
- Regelextraktion: Umwandlung des Entscheidungsbaums in eine Reihe von für den Menschen lesbaren Regeln, die die Bedingungen erklären, die zu bestimmten Vorhersagen führen.
- Partielle Abhängigkeitsdiagramme: Visualisierung der Beziehung zwischen einem Merkmal und dem vorhergesagten Ergebnis, wobei andere Merkmale konstant gehalten werden, um die Auswirkungen von Merkmalen besser zu verstehen.
- SHAP (SHapley Additive exPlanations): Eine Technik, die ein einheitliches Maß für die Bedeutung von Merkmalen bietet und zur intuitiven Erklärung einzelner Vorhersagen verwendet werden kann.
Die Erklärbarkeit ist nicht nur wichtig, um Vertrauen in das Modell zu gewinnen, sondern auch, um potenzielle Verzerrungen und ethische Erwägungen zu erkennen.
Wie werden Entscheidungsbäume analysiert?
Die Analyse von Entscheidungsbäumen ist eine kritische Phase im Arbeitsablauf des maschinellen Lernens, in der die Ergebnisse und Erkenntnisse aus einem Entscheidungsbaummodell untersucht und interpretiert werden. Diese Analyse geht über das Training und die Evaluierung des Modells hinaus, indem sie tiefer in das Verständnis eindringt, wie der Baum Entscheidungen trifft und wertvolle Informationen extrahiert. Im Folgenden werden die wichtigsten Aspekte der Entscheidungsbaumanalyse untersucht.
Modell-Interpretation
Die Interpretation eines Entscheidungsbaums ist ein grundlegender Schritt in der Analyse. Es geht darum zu verstehen, wie der Baum Merkmale und Kriterien verwendet, um Vorhersagen oder Klassifizierungen zu treffen. Dies beinhaltet:
- Wichtigkeit der Merkmale: Es muss festgestellt werden, welche Features im Entscheidungsprozess eine wichtige Rolle spielen. Entscheidungsbäume können Merkmalswichtigkeitsscores liefern, die Ihnen helfen, Prioritäten zu setzen und sich auf einflussreiche Attribute zu konzentrieren.
- Knotenauswertung: Untersuchen Sie einzelne Knoten im Baum, um die angewandten Entscheidungsregeln und -kriterien zu verstehen. Bei der Klassifizierung kann dies die Analyse der Gini-Verunreinigung oder der Entropiewerte beinhalten. Bei der Regression sollten Sie den mittleren quadratischen Fehler (MSE) oder andere relevante Metriken bewerten.
- Baumstruktur: Visualisieren Sie die Baumstruktur, um die Hierarchie der Entscheidungen und Zweige zu erkennen. Das Verständnis der Baumstruktur kann Aufschluss darüber geben, welche Merkmale den größten Einfluss auf das Ergebnis haben.
Regelextraktion
Die Regelextraktion ist der Prozess der Übersetzung des Entscheidungsbaums in eine Reihe von für den Menschen lesbaren Regeln. Diese Regeln erklären, wie das Modell Entscheidungen auf der Grundlage der eingegebenen Merkmale trifft. Die extrahierten Regeln werden oft in einem Format wie "Wenn-dann"-Anweisungen dargestellt. Zum Beispiel:
Wenn (Merkmal A > X) und (Merkmal B <= Y), dann Klasse 1
Wenn (Merkmal A <= X) und (Merkmal C > Z), dann Klasse 2
Die extrahierten Regeln bieten eine klare und prägnante Möglichkeit, die Entscheidungslogik des Modells den Beteiligten und Fachleuten zu erklären, was die Transparenz und das Vertrauen in das Modell erhöht.
Visualisierungen
Die Visualisierung des Entscheidungsbaums und der damit verbundenen Metriken kann die Analyse unterstützen. Zu den Visualisierungstechniken gehören:
- Baumdiagramme: Visuelle Darstellungen der Entscheidungsbaumstruktur mit Knoten, Verzweigungen und Blattknoten. Diese Diagramme bieten einen Überblick über die Entscheidungshierarchie auf hoher Ebene.
- Knotenattribute: Visualisierungserweiterungen, wie z. B. die Farbcodierung von Knoten auf der Grundlage von Klassenverteilungen oder das Hinzufügen von Beschriftungen mit Merkmalsnamen und Aufteilungskriterien, machen den Baum informativer.
- Partielle Abhängigkeitsdiagramme: Diese Diagramme zeigen, wie die Werte eines bestimmten Merkmals die Vorhersagen beeinflussen, während andere Merkmale konstant bleiben. Sie helfen Analytikern, die Auswirkungen von Merkmalen zu verstehen.
Fehleranalyse
Die Analyse der vom Entscheidungsbaum verursachten Fehler ist für die Modellverbesserung von entscheidender Bedeutung. Untersuchen Sie die Fälle, in denen die Vorhersagen des Modells von den tatsächlichen Ergebnissen abweichen. Zu den Aspekten der Fehleranalyse gehören:
- Muster der Fehlklassifizierung: Identifizieren Sie gemeinsame Muster oder Merkmale unter den Instanzen, die das Modell durchweg falsch klassifiziert. Diese Erkenntnisse können die Entwicklung von Merkmalen oder Modellanpassungen unterstützen.
- Ausreißer: Untersuchen Sie Instanzen, die für das Modell eine Herausforderung darstellen. Ausreißer können auf Datenanomalien oder die Notwendigkeit einer speziellen Behandlung hinweisen.
- Überanpassung: Prüfen Sie auf Anzeichen von Überanpassung, indem Sie die Komplexität des Baums und seine Fähigkeit zur Verallgemeinerung auf ungesehene Daten bewerten. Um die Überanpassung abzuschwächen, kann es notwendig sein, den Baum zu beschneiden und die Hyperparameter anzupassen.
Bewertung der geschäftlichen Auswirkungen
Berücksichtigen Sie die praktischen Auswirkungen der Vorhersagen und Klassifizierungen des Entscheidungsbaums. Beurteilen Sie, wie die Erkenntnisse des Modells in umsetzbare Entscheidungen umgesetzt werden können, sei es bei der Empfehlung von Marketingstrategien, der Zuweisung von Ressourcen oder der Erstellung medizinischer Diagnosen. Bewerten Sie die potenziellen Vorteile und Risiken, die mit dem Einsatz des Modells in der Praxis verbunden sind.
Die Entscheidungsbaumanalyse ist ein iterativer und explorativer Prozess, der Datenwissenschaftlern, Analysten und Interessengruppen hilft, ein tieferes Verständnis des Modellverhaltens und der Entscheidungsfindung zu erlangen. Durch Interpretation, Regelextraktion, Visualisierung, Fehleranalyse und Bewertung der geschäftlichen Auswirkungen können Sie wertvolle Erkenntnisse gewinnen und sicherstellen, dass Ihr Entscheidungsbaummodell mit den Zielen und Anforderungen Ihrer spezifischen Anwendung übereinstimmt.
Best Practices für Entscheidungsbäume
Zur effektiven Entwicklung und Bereitstellung von Entscheidungsbaummodellen müssen Sie sich an bewährte Verfahren halten und verschiedene praktische Aspekte berücksichtigen. Lassen Sie uns einige wichtige Überlegungen näher betrachten.
Datenerfassung und Feature Engineering
Die Qualität Ihrer Daten und die von Ihnen verwendeten Merkmale haben einen erheblichen Einfluss auf die Leistung Ihrer Entscheidungsbaummodelle. Hier sind einige Tipps:
- Datenqualität: Stellen Sie sicher, dass Ihre Daten sauber, frei von Ausreißern und richtig beschriftet sind.
- Merkmalsauswahl: Wählen Sie sorgfältig relevante Features aus und vermeiden Sie die Verwendung redundanter oder irrelevanter Features.
- Feature Engineering: Erstellen Sie neue Merkmale, die wertvolle Informationen erfassen, oder wandeln Sie vorhandene Merkmale um, um die Modellleistung zu verbessern.
- Data Scaling: Normalisieren oder standardisieren Sie die Merkmale, insbesondere wenn Sie Algorithmen verwenden, die auf die Größe der Merkmale reagieren.
Die richtige Datenvorbereitung und die Entwicklung von Merkmalen können die Vorhersagekraft Ihres Modells erheblich verbessern.
Modellbereitstellung
Der Einsatz eines Entscheidungsbaummodells in einer realen Anwendung umfasst mehrere Schritte:
- Skalierbarkeit: Stellen Sie sicher, dass Ihr Modell die erwartete Last und das Datenvolumen in der Produktion bewältigen kann.
- Integration: Integrieren Sie das Modell nahtlos in Ihre Anwendung oder Ihr System und berücksichtigen Sie dabei API-Endpunkte und Datenflüsse.
- Überwachung: Implementieren Sie Überwachungssysteme, um die Modellleistung zu verfolgen und Anomalien oder Abweichungen zu erkennen.
- Sicherheit: Schützen Sie sensible Daten und Modellendpunkte vor potenziellen Bedrohungen.
Die verantwortungsvolle und sichere Bereitstellung eines Modells ist ebenso wichtig wie die Erstellung eines genauen Modells.
Überwachung und Wartung
Modelle, einschließlich Entscheidungsbäume, müssen ständig überwacht und gewartet werden:
- Regelmäßige Aktualisierungen: Aktualisieren Sie Ihr Modell, sobald neue Daten verfügbar sind, um seine Genauigkeit zu erhalten.
- Überwachung der Datenabweichung: Überwachen Sie kontinuierlich die Datenabweichung, um sicherzustellen, dass Ihr Modell relevant bleibt und auch unter sich ändernden Bedingungen gut funktioniert.
- Nachschulung: Legen Sie Umschulungspläne fest, um das Modell mit den sich entwickelnden Mustern in den Daten auf dem neuesten Stand zu halten.
Proaktive Überwachung und Wartung verhindern, dass Modelle veraltet sind oder ungenaue Vorhersagen machen.
Ethische Erwägungen
Berücksichtigen Sie bei der Arbeit mit Entscheidungsbaummodellen die ethischen Implikationen:
- Erkennung und Abschwächung von Verzerrungen: Identifizieren und entschärfen Sie Verzerrungen in Ihren Daten und Modellvorhersagen, um faire Ergebnisse zu gewährleisten.
- Transparenz: Machen Sie die Funktionsweise des Modells transparent und bemühen Sie sich, seine Entscheidungen zu erklären.
- Datenschutz: Schützen Sie sensible Informationen bei der Erfassung und Verwendung von Daten für das Modelltraining.
- Einhaltung der Vorschriften: Halten Sie sich an die einschlägigen Datenschutzbestimmungen, wie GDPR oder HIPAA.
Die Sicherstellung ethischer Praktiken bei der Modellentwicklung ist entscheidend für den Aufbau von Vertrauen und die Vermeidung von rechtlichen und Reputationsrisiken.
Wenn Sie diese praktischen Tipps und Best Practices befolgen, können Sie die Effektivität Ihrer Entscheidungsbaummodelle maximieren und gleichzeitig ethische Standards einhalten und ihre Zuverlässigkeit in realen Anwendungen sicherstellen.
Entscheidungsbaum-Vorlage
Eine Entscheidungsbaumvorlage dient als strukturierter Rahmen oder Entwurf für die Erstellung von Entscheidungsbäumen beim maschinellen Lernen. Sie bietet einen standardisierten Ansatz zum Entwerfen und Erstellen von Entscheidungsbäumen, wodurch der Modellentwicklungsprozess effizienter und organisierter wird. Im Folgenden werden die wichtigsten Komponenten und Vorteile der Verwendung einer Entscheidungsbaumvorlage erläutert.
Komponenten einer Entscheidungsbaumvorlage
- Definition des Ziels: Definieren Sie eindeutig das Ziel Ihres Entscheidungsbaummodells. Wollen Sie einen Klassifizierungs- oder Regressionsbaum erstellen? Welches sind die spezifischen Ergebnisse oder Vorhersagen, die Sie erreichen möchten?
- Datenerfassung und -vorverarbeitung: Geben Sie die Datenquellen, die Datenerfassungsmethoden und die Datenvorverarbeitungsschritte an. Dazu gehören die Datenbereinigung, der Umgang mit fehlenden Werten, die Codierung kategorischer Variablen und die Skalierung numerischer Merkmale.
- Auswahl der Merkmale: Bestimmen Sie, welche Merkmale oder Attribute aus dem Datensatz als Eingabe für den Entscheidungsbaum verwendet werden sollen. Berücksichtigen Sie bei Ihrer Auswahl die Analyse der Merkmalsbedeutung.
- Aufteilungskriterien: Legen Sie die Kriterien fest, die der Entscheidungsbaum zum Aufteilen der Knoten verwenden soll. Typische Kriterien sind die Gini-Verunreinigung, die Entropie, der mittlere quadratische Fehler (MSE) oder das Verstärkungsverhältnis, je nach Art der Aufgabe (Klassifizierung oder Regression).
- Abstimmung der Hyperparameter: Definieren Sie die Hyperparameter, die abgestimmt werden müssen, z. B. die maximale Tiefe des Baums, die Mindeststichproben pro Blatt oder die Wahl des Kriteriums. Geben Sie den Bereich oder die Werte an, die während des Abstimmungsprozesses untersucht werden sollen.
- Modellschulung: Beschreiben Sie die Schritte für das Training des Entscheidungsbaums auf dem Trainingsdatensatz. Geben Sie alle Kreuzvalidierungstechniken oder Strategien zur Behandlung unausgewogener Daten an.
- Bewertungsmetriken: Bestimmen Sie die Bewertungsmetriken, die zur Beurteilung der Modellleistung verwendet werden sollen. Für die Klassifizierung kann dies Genauigkeit, Präzision, Wiedererkennung, F1-Score oder ROC-AUC umfassen. Bei der Regression können Sie Metriken wie den mittleren absoluten Fehler (MAE) oder das R-Quadrat (R²) berücksichtigen.
- Interpretierbarkeit und Visualisierung: Beschreiben Sie, wie die Ergebnisse des Modells visualisiert und interpretiert werden sollen. Entscheidungsbäume bieten eine inhärente Interpretierbarkeit, aber Sie können auch Techniken wie die Extraktion von Regeln oder partielle Abhängigkeitsdiagramme verwenden.
- Testen und Validierung: Definieren Sie das Verfahren zum Testen des trainierten Modells auf einem separaten Validierungsdatensatz oder durch Kreuzvalidierung. Stellen Sie sicher, dass das Modell gut auf ungesehene Daten generalisiert.
- Bereitstellungsplan: Skizzieren Sie gegebenenfalls die Schritte für den Einsatz des Entscheidungsbaummodells in einer Produktionsumgebung. Berücksichtigen Sie dabei Skalierbarkeit, Integration und Überwachung.
Vorteile der Verwendung einer Entscheidungsbaumvorlage
- Konsistenz: Durch eine Vorlage wird sichergestellt, dass alle Entscheidungsbäume innerhalb eines Projekts oder einer Organisation einer einheitlichen Struktur und Methodik folgen. Durch diese Konsistenz wird die Zusammenarbeit zwischen den Teammitgliedern vereinfacht und ein standardisierter Ansatz für die Modellentwicklung beibehalten.
- Effizienz: Vorlagen sparen Zeit, da sie eine vordefinierte Struktur und Richtlinien bereitstellen und somit die Notwendigkeit verringern, bei jedem neuen Projekt von vorne anzufangen. Diese Effizienz ist besonders wertvoll bei der Arbeit an mehreren Aufgaben des maschinellen Lernens.
- Dokumentation: Entscheidungsbaumvorlagen dienen als Dokumentation für Ihren Modellierungsprozess. Sie erfassen kritische Entscheidungen, Hyperparameter und Bewertungskriterien und erleichtern so das Verständnis und die Reproduktion der Ergebnisse.
- Qualitätskontrolle: Vorlagen erleichtern die Qualitätskontrolle, indem sie die Modellentwickler durch bewährte Praktiken und Standardverfahren führen. Auf diese Weise lassen sich häufige Fallstricke und Fehler vermeiden.
- Wiederverwendbarkeit: Sie können Entscheidungsbaumvorlagen für ähnliche Aufgaben oder Projekte anpassen und wiederverwenden, was sie zu einem wertvollen Bestandteil Ihres Toolkits für maschinelles Lernen macht.
- Wissenstransfer: Vorlagen unterstützen den Wissenstransfer innerhalb von Teams oder Organisationen. Neue Teammitglieder können sich schnell in den Modellierungsprozess einarbeiten und sich an die festgelegten Standards halten.
- Einhaltung von Vorschriften: In regulierten Branchen können Entscheidungsbaumvorlagen dazu beitragen, die Einhaltung branchenspezifischer Richtlinien und Vorschriften zu gewährleisten.
- Iterative Verbesserung: Vorlagen können im Laufe der Zeit mit den gewonnenen Erfahrungen und Erkenntnissen weiterentwickelt werden, so dass Sie Ihren Entscheidungsbaum-Modellierungsprozess kontinuierlich verfeinern und verbessern können.
Wenn Sie eine Entscheidungsbaumvorlage in Ihren Arbeitsablauf für maschinelles Lernen integrieren, können Sie die Effizienz, Konsistenz und Qualität Ihrer Modellierungsbemühungen verbessern. Unabhängig davon, ob Sie ein Anfänger oder ein erfahrener Datenwissenschaftler sind, kann eine gut strukturierte Vorlage eine wertvolle Ressource für die erfolgreiche Anwendung von Entscheidungsbäumen auf verschiedene reale Probleme darstellen.
Fazit zu Entscheidungsbäumen
Entscheidungsbäume sind robuste und interpretierbare Modelle, die Sie beim maschinellen Lernen einsetzen können. Von der Klassifizierung von Spam-E-Mails bis hin zur Vorhersage von Immobilienpreisen - Entscheidungsbäume haben ein breites Anwendungsspektrum. Denken Sie daran, den geeigneten Algorithmus auszuwählen, Ihr Modell fein abzustimmen und ethische Überlegungen zu berücksichtigen. Mit dem Wissen und den Fertigkeiten, die Sie in diesem Leitfaden erworben haben, sind Sie gut gerüstet, um Ihre Reise durch das maschinelle Lernen mit Entscheidungsbäumen als treuen Begleitern anzutreten.
Aber die Reise ist hier noch nicht zu Ende. Das Gebiet des maschinellen Lernens ist riesig und entwickelt sich ständig weiter. Bleiben Sie also am Ball, experimentieren Sie und verschieben Sie die Grenzen dessen, was Sie mit Entscheidungsbäumen und anderen maschinellen Lerntechniken erreichen können. Mit Engagement und kontinuierlichem Lernen werden Sie noch mehr Möglichkeiten erschließen und bemerkenswerte Fortschritte in der aufregenden Welt der Datenwissenschaft und künstlichen Intelligenz machen.
Wie erstellt man einen Entscheidungsbaum in wenigen Minuten?
Wir stellen Ihnen Appinio vor, die Echtzeit-Marktforschungsplattform, die Ihnen die Möglichkeit gibt, schnelle datengestützte Entscheidungen zu treffen. Mit Appinio war die Durchführung Ihrer eigenen Marktforschung noch nie so aufregend und zugänglich. Hier erfahren Sie, warum Sie Appinio für die Sammlung von Daten für Ihre Entscheidungsbäume lieben werden:
- Blitzschnelle Einblicke: Sie können innerhalb von Minuten von Fragen zu Erkenntnissen gelangen und so sicherstellen, dass Sie die benötigten Daten genau dann erhalten, wenn Sie sie für Ihre Entscheidungsbaummodelle benötigen.
- Benutzerfreundlichkeit: Sie brauchen keinen Doktortitel in Forschung. Unsere Plattform ist so intuitiv, dass sie von jedem genutzt werden kann. So können Sie mühelos wertvolle Erkenntnisse über Verbraucher gewinnen.
- Globale Reichweite: Definieren Sie Ihre Zielgruppe aus einem reichhaltigen Pool von über 1.200 Merkmalen und Umfrageteilnehmern in über 90 Ländern und erhalten Sie so eine globale Perspektive für Ihre Entscheidungsbäume.


